# A tibble: 10 × 5
anzsco22 anzsco22_descr isco8 partial isco8_descr
<chr> <chr> <chr> <chr> <chr>
1 111111 Chief Executive or Managing Director 1112 p Senior governmen…
2 111111 Chief Executive or Managing Director 1114 p Senior officials…
3 111111 Chief Executive or Managing Director 1120 p Managing directo…
4 111211 Corporate General Manager 1112 p Senior governmen…
5 111211 Corporate General Manager 1114 p Senior officials…
6 111211 Corporate General Manager 1120 p Managing directo…
7 111212 Defence Force Senior Officer 0110 p Commissioned arm…
8 111311 Local Government Legislator 1111 p Legislators
9 111312 Member of Parliament 1111 p Legislators
10 111399 Legislators nec 1111 p Legislators Advances in Ex-Post Harmonisation using Graph Representations of Cross-Taxonomy Transformations
Cynthia Huang with A. Prof. Laura Puzzello
Department of Econometrics and Business Statistics
Oct 31, 2023
Overview
- Introduction to Data Preparation Task
- Ex-Post Harmonisation
- Cross-Taxonomy Transformation
- ANZSCO22 Example
- Background and Existing Approaches
- Crossmap Approach
- Discussion of Implications
Introduction to Data Preparation Task
Ex-Post Harmonisation
Ex-post (or retrospective) data harmonization refers to procedures applied to already collected data to improve the comparability and inferential equivalence of measures from different studies (Kołczyńska 2022; Fortier et al. 2016; Ehling 2003)
Typical cases in Official Statistics involve different taxonomies across space and/or time:
- Labour Statistics: adding and deleting occupation codes
- Macroeconomic and Trade Data: evolving product/industry classifications; changing country boundaries
- Census and Election Data: changing statistical survey or electoral boundaries
Sub-Tasks in Ex-Post Harmonisation
Ex-post harmonisation involves a number of related data wrangling tasks including selecting approriate transformations, and then implementing and validating them on data.
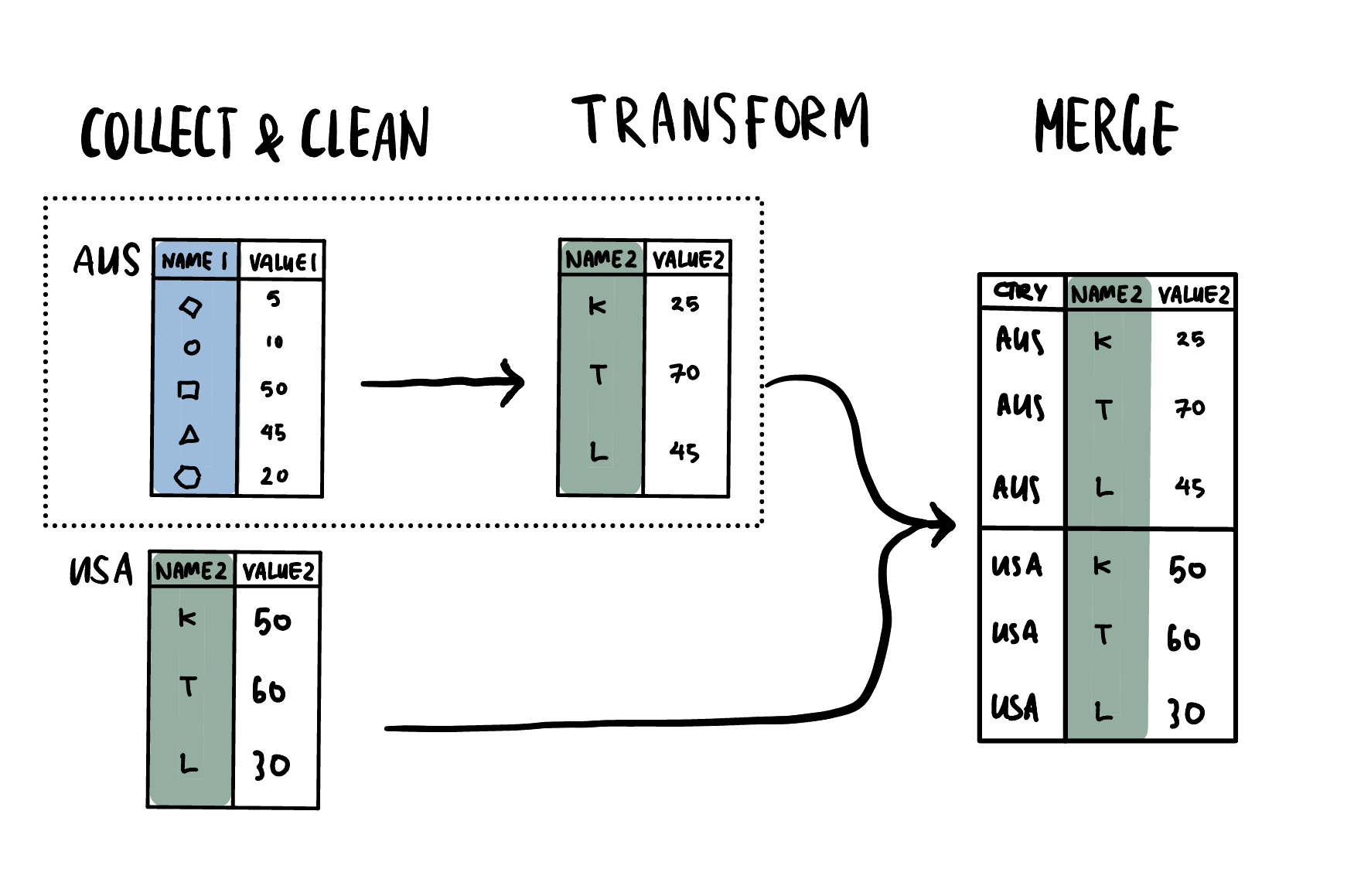
ANZSCO22 Example
- Data collected using the Australian and New Zealand Standard Classification of Occupations (ANZSCO) is not directly comparable with data collected using the International Standard Classification of Occupations (ISCO).
# A tibble: 6 × 2
anzsco22 anzsco22_descr
<chr> <chr>
1 111111 Chief Executive or Managing Director
2 111211 Corporate General Manager
3 111212 Defence Force Senior Officer
4 111311 Local Government Legislator
5 111312 Member of Parliament
6 111399 Legislators nec ANZSCO22 Example
- The Australian Bureau of Statistics (ABS) has developed a crosswalk between ANZSCO and ISCO8.
ANZSCO22 Example
- Combining AUS data with USA data requires transforming each country’s observations into a common taxonomy (e.g. ANZSCO22 -> ISCO8).
# A tibble: 6 × 2
anzsco22 count
<chr> <dbl>
1 111111 1000
2 111211 500
3 111212 40
4 111311 300
5 111312 150
6 111399 10Cross-Taxonomy Transformations
We use the term cross-taxonomy transformation to refer to the sub-task of taking observations collected using a source taxonomy, and transforming it into “counter-factual” observations indexed by a target taxonomy.
- Source/Target Taxonomy: a set of categories (e.g. occupation codes, product codes, etc.) according to which data is collected or transformed into. (e.g.
anzsco22andisco8) - Category Indexed Values: a set of (numeric) values indexed by a taxonomy (e.g. rows in
anzsco22_stats) - Observation: A set of category indexed values for a given unit of observation (e.g. the table
anzsco22_stats)
Background and Existing Approaches
Existing Approaches
- implementations are highly varied and idiosyncratic
- auditing & reuse depends on readability of source code
- data quality validation is ad-hoc and unlikely to be comprehensive
Motivation for New Approach
- Standardised workflows can:
- improve code readability and reuse, and
- reduce errors
- see Domain Specfic Languages for data preparation (Wickham 2014; Kandel et al. 2011)
- Statistical properties of complex data pre-processing are not as well understood or studied compared to simpler transformations (e.g. missing data imputation, outlier detection, etc.)
- formal structures and frameworks can enable more rigorous anlaysis of these properties
- e.g. Blocker and Meng (2013) propose a theoretical framework for multi-phase inference
Crossmap Approach
Crossmaps as Information Structures
- a crossmap is an information and data structure for encoding and applying cross-taxonomy transformations
- separates transformation logic from implementation
- allows for data validation using graph conditions
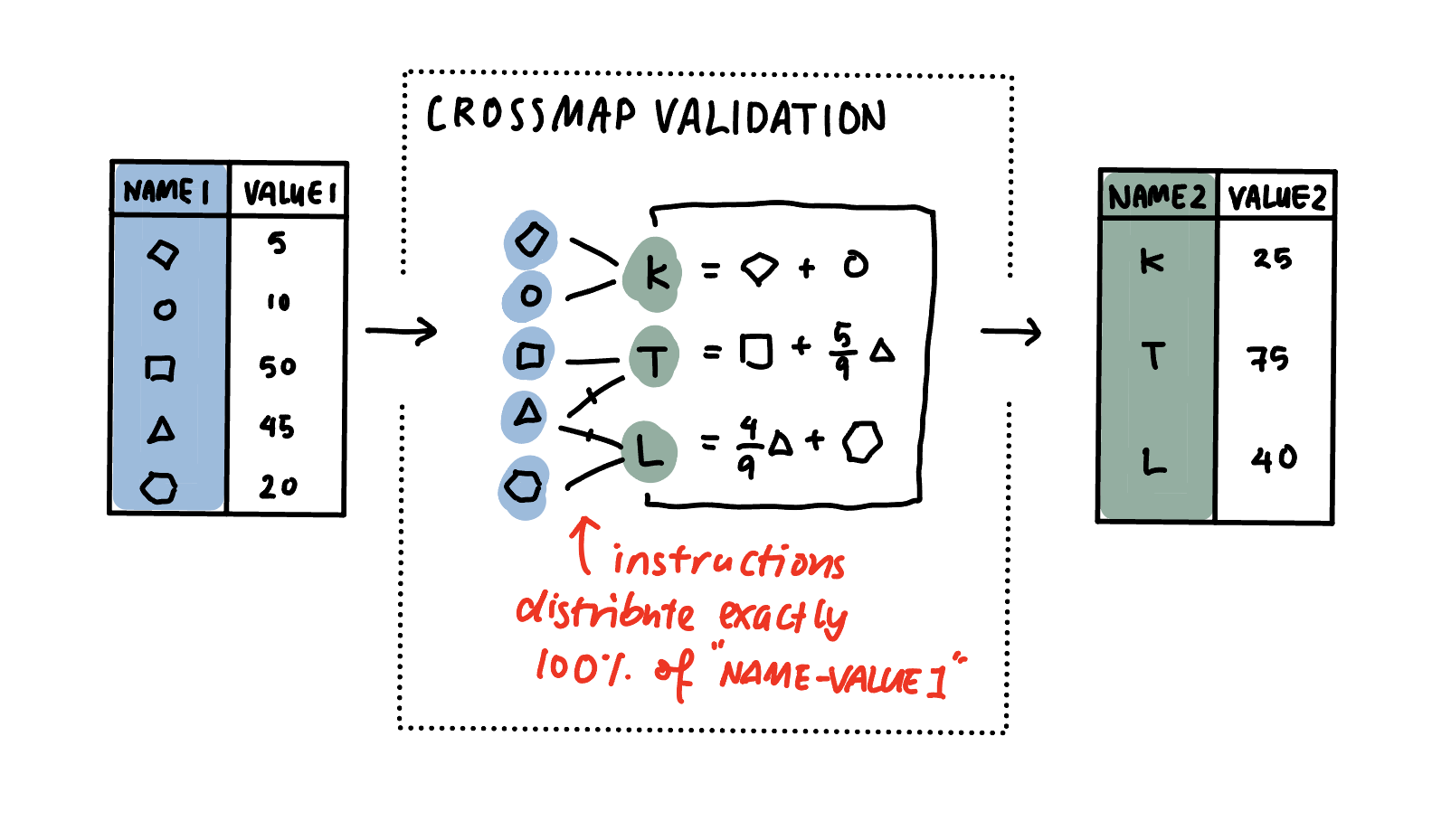
Crossmaps as Graphs
Bi-Partite Graph: the source and target taxonomies form two disjoint sets of nodes, and weighted edges specify how numeric data is passed between the two taxonomies.
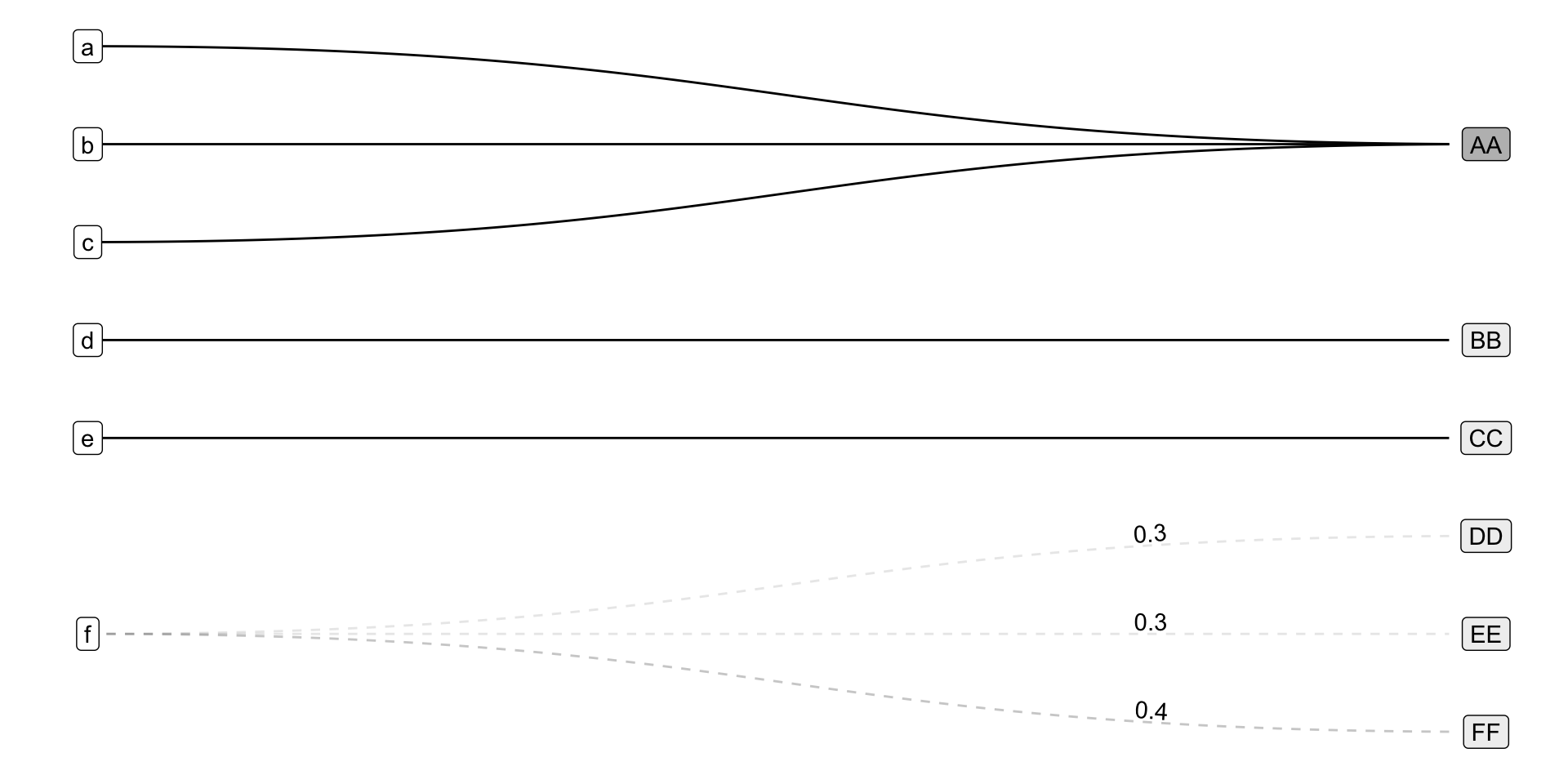
Crossmaps and Conditional Probability Distributions
Conditional Probabilities: Conditional on an “individual” being observed in category f, the probability of them transitioning to category DD in the counterfactual is 0.3 – i.e. \(Pr(DD|f) = 0.3\)
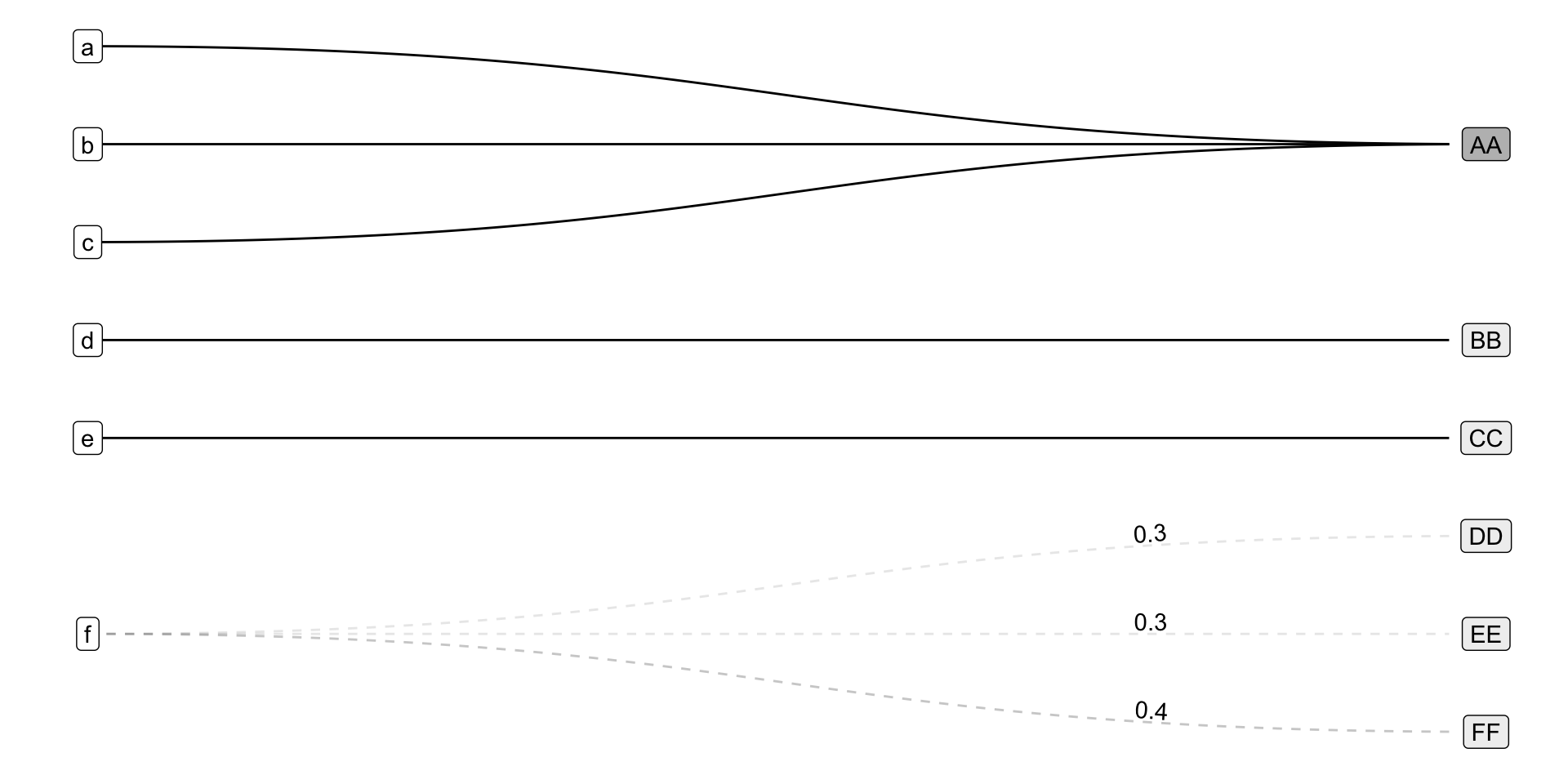
Other useful representations
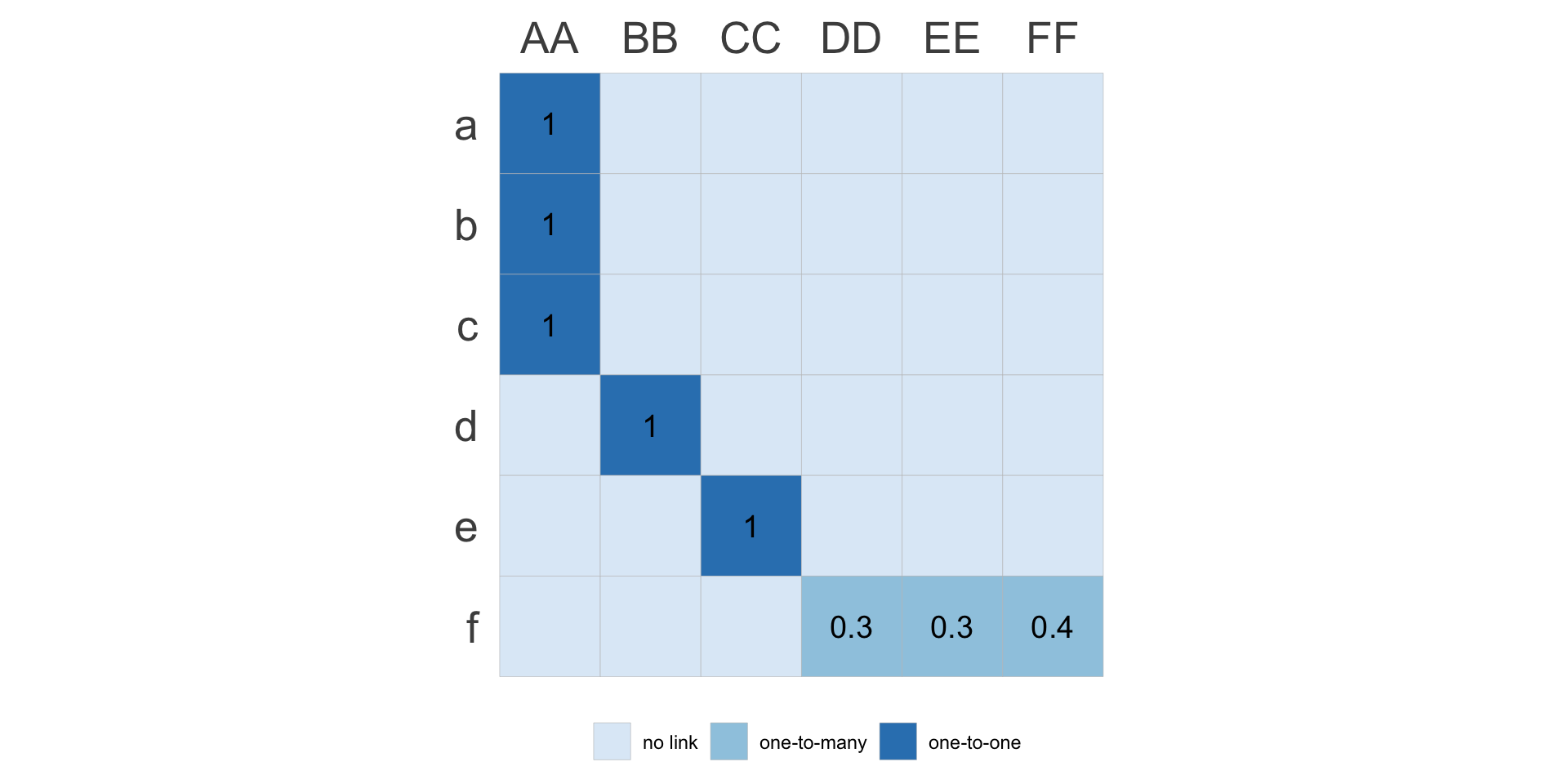
Transition/Adjacency Matrix representation highlights the fact that cross-taxonomy transformations are a special case of Markov Chains.
Edge List representation allows for the transformation to implemented as a series of database joins.
xmap_df:
recode, split, and collapse
(from -> to) BY weights
from to weights
1 a AA 1.0
2 b AA 1.0
3 c AA 1.0
4 d BB 1.0
5 e CC 1.0
6 f DD 0.3
7 f EE 0.3
8 f FF 0.4Cross-taxonomy transformation using database operations
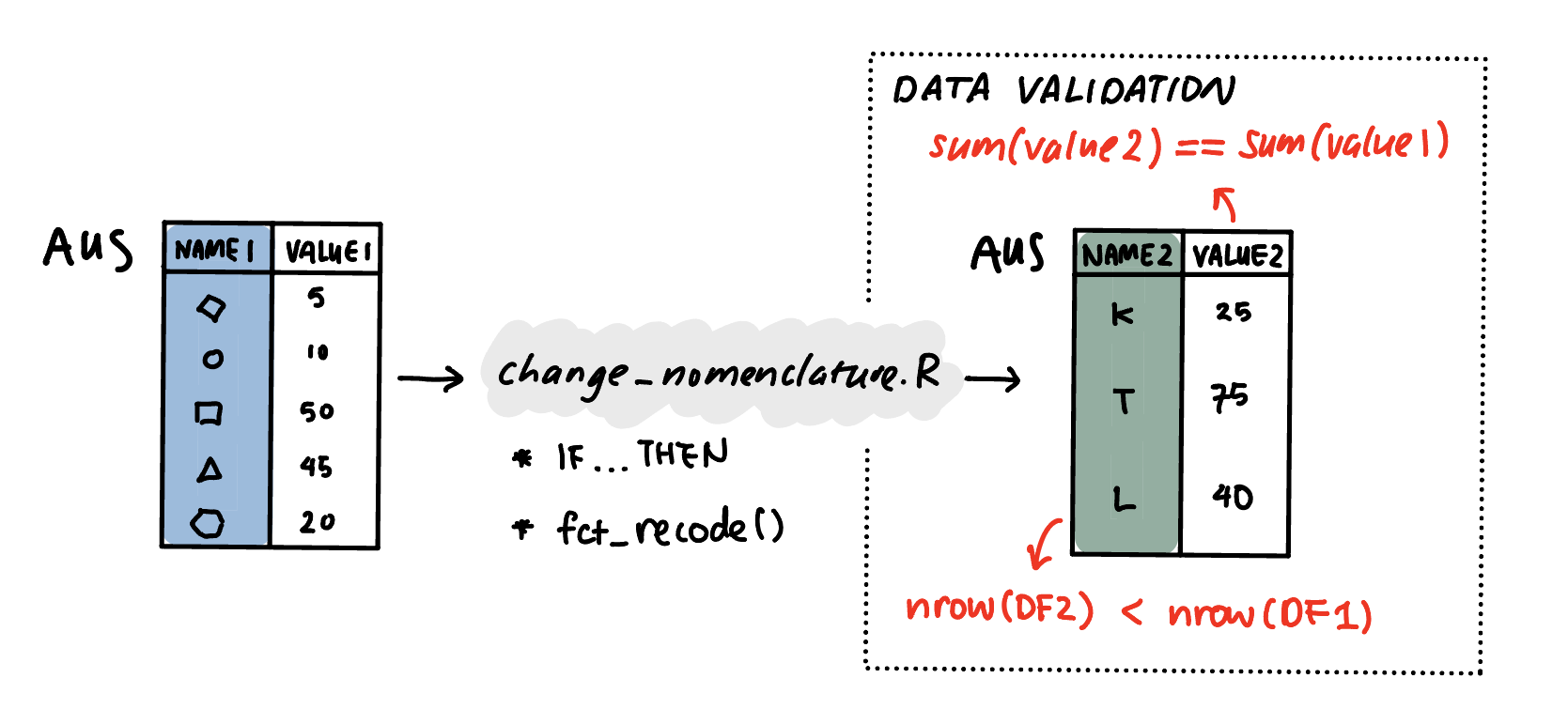
- Cross-taxonomy transformation always involves renaming category labels:
111212: Defence Force Senior Officer--> 0110: Commissioned armed forces officers.
- In addition to these character transformation, depending on the mapping between taxonomies, numeric transformation can include:
- “pass-through” of numeric values – i.e. one-to-unique relations
- numeric aggregation – i.e. one-to-shared relations
- numeric redistribution – i.e. one-to-many relations
Cross-taxonomy transformation using database operations
We can encompass the string and numeric operations in the following tabular operations:
- Rename original categories into target categories
- Multiply source node values by link weight.
- Summarise mutated values by target node.
Discussion
Benefits and implications
- Data quality
- assertions for validating transformation logic and conformability
- prescribes data cleaning order
- Statistical Properties of Cross-Taxonomy Transformations
- theoretical vs. empirical robustness
- complex imputation metrics
- Data provenance
- improved code-readabilty
- new provenance documentation and visualisation formats
- extracting new summary insights from existing transformation scripts
Implications for Validing Transformation Logic
- A valid cross-taxonomy transformation should preserve the total of category index values in each source observation.
- A crossmap has valid transformation logic if every source node and its outgoing links define a valid probability distribution – i.e. the sum of the edge weights is 1.

Implications for Validing Conformability
For a crossmap and some source data to be conformable, the transformation logic should cover all categories in the source data:
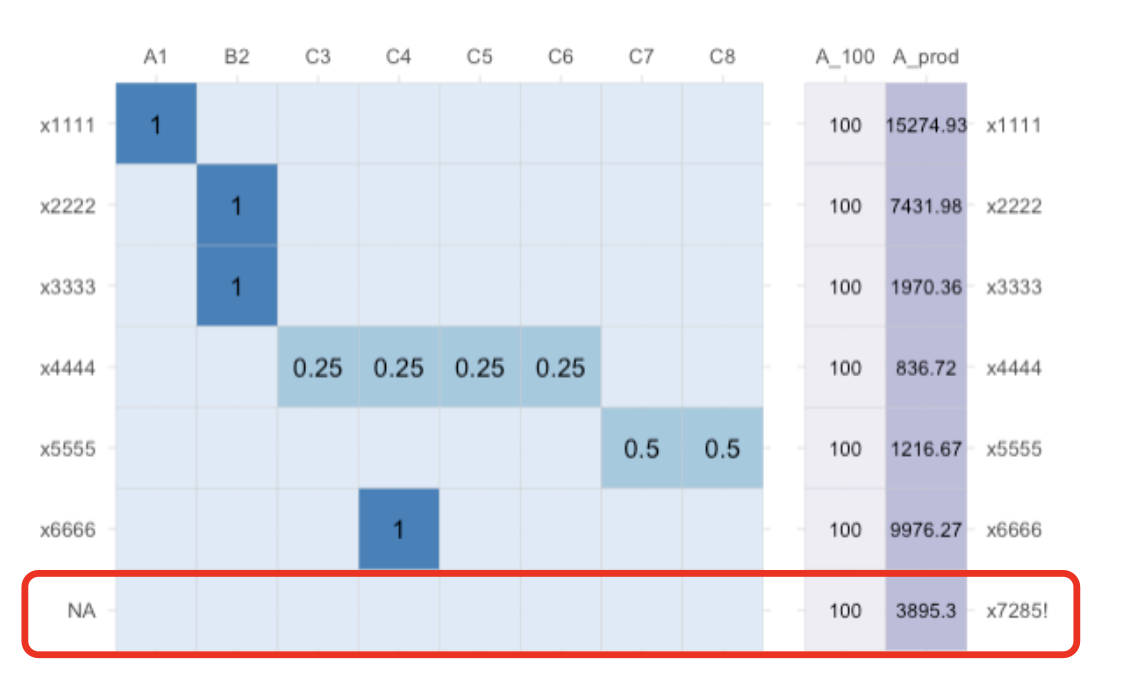
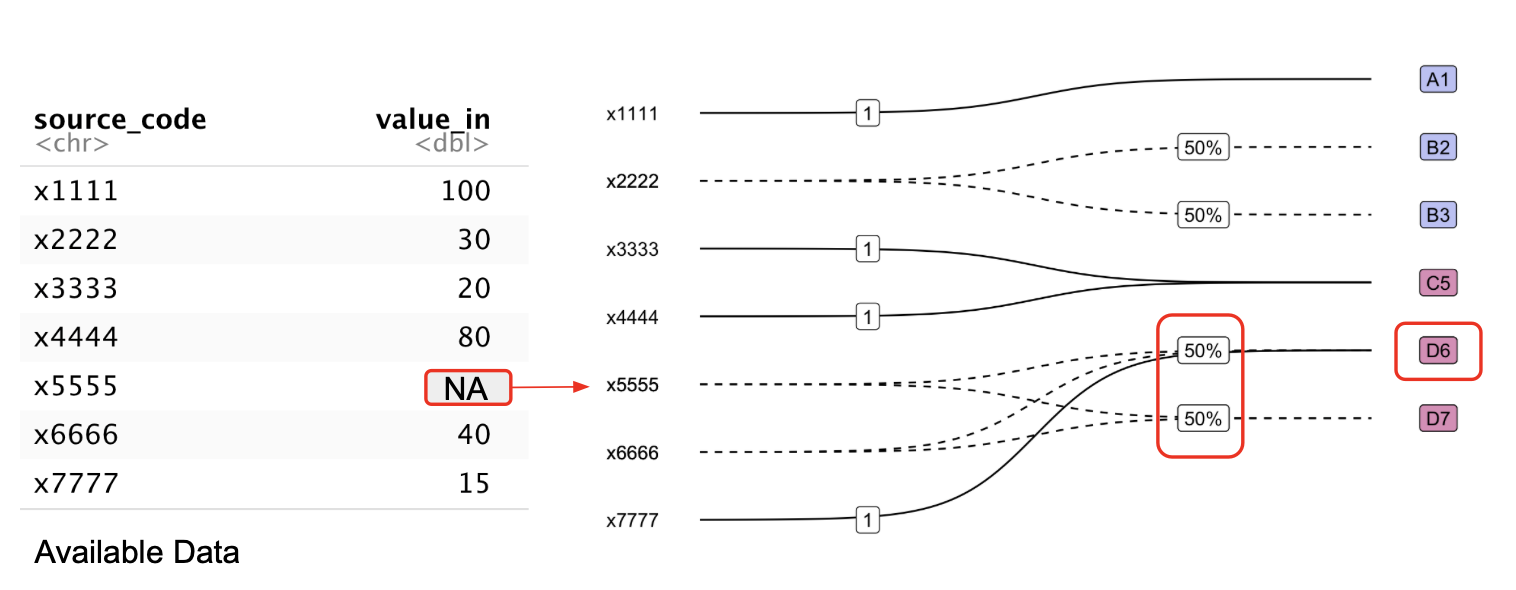
Implications for Data Preprocessing Workflow
Missing values cannot be meaningfully distributed across multiple categories, so missing values should be dealt with before the cross-taxonomy transformation.
Implications for Understanding Statistical Properties
- Theoretically valid cross-taxonomy transformation logic does not guaranteee the transformed data can support downstream inference or estimation.
- In practice, the quality of the transformed data depends on the quality of the source data, the quality of the crossmap, and the degree of imputation performed on the source data.
- Cross-taxonomy transformations are a complex imputation procedure. Unlike with missing value imputation, it is not immediately clear how to define metrics for measuring the degree of this imputation. However, the framework suggests that such a metric needs to incorporate properities of crossmaps as well as the distance between the source and transformed data.
- Crossmaps define a class of graphs from which we can generate alternative transformations for a given set of source observations. These alternative transformations can then be applied to examine the robustness of downstream analysis to different pre-processing (i.e. mapping) decisions.
Implications for Code Readability
Just THREE lines of R code to transform data using a validated crossmap:
hssicnaics <- read_csv("naics_xmap.csv")
src_data <- read_csv("prod_data.csv")
final_data <- apply_xmap(.data = prod_data, .xmap = hssicnaics)Compared to hundreds for imperative algorithms (e.g. STATA code below):
hssicnaics_20191205/schott_algorithm_28.do [800+ lines]
/*
HS-SIC-NAICS- Concordance Project
This program
1. reads in the hs-sic and hs-naics concordances from the monthly trade cd files and
from Census and uses two mechanical matches to fill in naics matches prior to 2000 and sic
matches after 2001.
2. Although step 1 succeeds in generating many matches, there are some that remain unmatched.
these were given to an RA (thanks kitjawat!) to match by hand. These hand matches are merged in
after the mechanical matches. (Note that one typo in the handmatched file is fixed in this .do file.
3. In the future, we intend to explore using our hs-over-time concordances to avoid the need for any
hand-matching.
copyright Peter K. Schott / Justin R. Pierce
This program, associated files and a working paper describing our overall HS-SIC-NAICS concordance effort
can be found at http://www.som.yale.edu/faculty/pks4/
2008.08.21 first version
2009.10.16 current version
2016.7.27 restored the older practice (89-106) of keeping SIC and naics codes as strings
so, in key place, subbed back in code from v20
also updated to use concordances from 89-115
2018.7.16 moved this all to /research/schott_trade_website
added the NAICSX codes
*/
**0 Prelim
clear
set more off
/*
global MC "D:\Dropbox (yale som economics)\research\schott_trade_website\hs_sic_naics\input\m_concordance\"
global XC "D:\Dropbox (yale som economics)\research\schott_trade_website\hs_sic_naics\input\x_concordance\"
global NC "D:\Dropbox (yale som economics)\research\schott_trade_website\hs_sic_naics\input\naics\"
global C "D:\Dropbox (yale som economics)\research\schott_trade_website\hs_sic_naics\"
global CI "D:\Dropbox (yale som economics)\research\schott_trade_website\hs_sic_naics\interim"
*/
global MC "/io/jrp_research/schott_trade_website/hs_sic_naics/input/m_concordance/"
global XC "/io/jrp_research/schott_trade_website/hs_sic_naics/input/x_concordance/"
global NC "/io/jrp_research/schott_trade_website/hs_sic_naics/input/naics/"
global C "/io/jrp_research/schott_trade_website/hs_sic_naics/"
global CI "/io/jrp_research/schott_trade_website/hs_sic_naics/interim/"
cd "$C"
*0 prep new (post 2016) concordances
/*
foreach y in "16" "17" {
foreach m in "12" /*"01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12"*/ {
cd d:\data\raw_yale_trade\monthly
unzipfile EXDB`y'`m', replace
infix ///
double commodity 1-10 ///
str descrip_1 11-160 ///
str descrip_2 161-210 ///
str quantity_1 211-213 ///
str quantity_2 214-216 ///
double sitc 217-221 ///
double end_use 222-226 ///
str naics 227-232 ///
usda 233-233 ///
hitech 234-235 ///
using CONCORD.TXT, clear
label var commodity "10-Digit Harmonized Tariff Schedule (HTS) Code"
label var descrip_1 "150 digit description"
label var descrip_2 "50 digit description"
label var quantity_1 "3-digit unit of q 1"
label var quantity_2 "3-digit unit of q 1"
cd "$XC"
save concord_1`y', replace
}
}
foreach y in "16" "17" {
foreach m in "12" /*"01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12"*/ {
cd d:\data\raw_yale_trade\monthly
unzipfile IMDB`y'`m', replace
infix ///
double commodity 1-10 ///
str descrip_1 11-160 ///
str descrip_2 161-210 ///
str quantity_1 211-213 ///
str quantity_2 214-216 ///
double sitc 217-221 ///
double end_use 222-226 ///
str naics 227-232 ///
usda 233-233 ///
hitech 234-235 ///
using CONCORD.TXT, clear
label var commodity "10-Digit Harmonized Tariff Schedule (HTS) Code"
label var descrip_1 "150 digit description"
label var descrip_2 "50 digit description"
label var quantity_1 "3-digit unit of q 1"
label var quantity_2 "3-digit unit of q 1"
cd "$MC"
save concord_20`y', replace
}
}
*/
**1 Assemble the concordance files from the Census trade
*files for the years 1989-2017
*1.1 Imports
cd "$MC"
use concord_1989, clear
gen year=1989
forvalues y=1990/2017 {
display["`y'"]
append using concord_`y'
replace year=`y' if year==.
if `y' <2000 {
keep commodity year sic
}
if `y' >=2000 {
keep commodity year naics sic
}
if `y'==2005 {
rename commodity scommodity
destring scommodity, force g(commodity)
}
}
cd "$CI"
duplicates drop
save concord_m_1989_2017_abbreviated, replace
*Check number of manufacturing codes
use concord_m_1989_2017_abbreviated, clear
gen man =substr(naics,1,1)=="3"
egen x = tag(naics year)
table year if x, c(sum man)
*1.2 Exports
cd "$XC"
use concord_89, clear
gen year=89
forvalues y=90/117 {
display["`y'"]
append using concord_`y'
replace year=`y' if year==.
*Note that NAICS codes are not reported until 2000
if `y' <100 {
keep commodity year sic
}
if `y' >=100 & `y'<=106 {
keep commodity year naics sic
}
if `y'==106 {
rename commodity scommodity
destring scommodity, force g(commodity)
rename sic ssic
}
if `y' >106 {
keep commodity year naics sic ssic
}
}
drop sic
rename ssic sic
replace year=year+1900
cd "$CI"
duplicates drop
save concord_x_1989_2017_abbreviated, replace
*check # man codes
*
* Dip in 2013 due to implementation of NAICS 2012
*
* But why recovery (somewhat) starting in 2014
*
use concord_x_1989_2017_abbreviated, clear
gen man =substr(naics,1,1)=="3"
egen x = tag(naics year)
table year if x, c(sum man)
**2 SIC Mapping
*Assigns SIC codes to HS codes for years after end of SIC
cd "$CI"
foreach zzz in x m {
*Create list of HS-SIC mappings for 2001
*(last year for which sic data are available)
use concord_`zzz'_1989_2017_abbreviated, clear
replace year=year-1900
keep if year==101
keep commodity sic
drop if sic==""
duplicates drop commodity, force
sort commodity
save `zzz'temp0, replace
*Match list of 2001 HS-SIC mappings to post-2001 years
use concord_`zzz'_1989_2017_abbreviated, clear
replace year=year-1900
keep if year>101
keep commodity
duplicates drop commodity, force
sort commodity
merge commodity using `zzz'temp0, keep(sic)
tab _merge
drop _merge
gen double hs=commodity
format hs %15.0fc
egen sic87=group(sic)
save `zzz'temp_01, replace
*Save two versions of group-naics mapping for below.
*These are simply used for labeling the source of
*HS-SIC matches.
use `zzz'temp_01, clear
collapse (mean) sic87, by(sic)
rename sic87 sic87_new1
rename sic sic_new1
drop if sic_new1=="" | sic87_new1==.
sort sic87_new1
save `zzz'temp1, replace
use `zzz'temp_01, clear
collapse (mean) sic87, by(sic)
rename sic87 sic87_new2
rename sic sic_new2
drop if sic_new2=="" | sic87_new2==.
sort sic87_new2
save `zzz'temp2, replace
*First Mechanical Match
*Look at SIC matches for HS10s within an HS9. If all non-missing
*SIC codes are the same, assign that SIC code to unmatched HS10s within
*that HS9. Repeat for higher levels of aggregation.
use `zzz'temp_01, clear
gen sic87_new1 = sic87
sum hs sic87*
quietly {
foreach x in 9 8 7 6 5 4 3 2 {
noisily display [`x']
local y = 10-`x'
gen hs`x' = int(hs/(10^`y'))
egen t1 = mean(sic87), by(hs`x')
egen t2 = sd(sic87), by(hs`x')
egen t3 = count(sic87), by(hs`x')
gen sic87_`x' = t1 if t2==0 | t3==1
replace sic87_new1 = sic87_`x' if sic87==. & sic87_new1==.
drop t1 t2 t3
drop hs`x' sic87_`x'
}
}
sum hs sic87 sic87_new1
sort hs
save `zzz'temp_02, replace
*Second Mechanical Match
*Sort HS codes. For unmatched HS codes (or contiguous groups of HS10
*codes), look at the matched HS10 codes that precede and follow. If
*matches for preceding and following HS10 codes are identical, assign
*that SIC code to the unmatched HS code(s).
use `zzz'temp_02, clear
gen sic87_new2 = sic87_new1
gen begin = 1 if sic87_new1==. & sic87_new1[_n-1]~=.
gen end = sic87_new1==. & sic87_new1[_n+1]~=.
gen bsum = sum(begin)
gen gap = sic87_new1==.
replace bsum=. if gap==0
gen sb = sic87_new1[_n-1]*begin
gen se = sic87_new1[_n+1]*end
egen tb = mean(sb), by(bsum)
egen te = mean(se), by(bsum)
gen match = tb==te
replace sic87_new2 = tb if match==1 & sic87_new1==.
sum hs sic87*
drop begin end bsum gap sb se tb te match
sort hs
save `zzz'temp_03, replace
*Merge in "group" codes created above, which are only used for labeling.
use `zzz'temp_03, clear
sort sic87_new1
merge sic87_new1 using `zzz'temp1, keep(sic_new1)
tab _merge
drop _merge
sort sic87_new2
merge sic87_new2 using `zzz'temp2, keep(sic_new2)
tab _merge
drop _merge
sort hs
gen t=sic87_new1~=.
tab t
drop t
drop sic87*
format hs %15.0g
drop if hs<100
format commodity %15.0fc
save `zzz'_concord_89_117_sicfillin, replace
}
**2 NAICS
*Assigns NAICS codes to HS codes for years before start of NAICS
cd "$CI"
foreach zzz in x m {
*Create list of HS-NAICS mappings for 2000
*(first year for which naics data are available)
use concord_`zzz'_1989_2017_abbreviated, clear
replace year=year-1900
keep if year==100
keep commodity naics
drop if naics==""
duplicates drop commodity, force
sort commodity
save `zzz'temp0, replace
*Match list of 2000 HS-NAICS mappings to pre-2000 years
use concord_`zzz'_1989_2017_abbreviated, clear
replace year=year-1900
keep if year<100
keep commodity
duplicates drop commodity, force
sort commodity
merge commodity using `zzz'temp0, keep(naics)
tab _merge
drop _merge
gen double hs=commodity
egen naics87=group(naics)
save `zzz'temp_01, replace
*Save two versions of group-naics mapping for below.
*These are simply used for labeling the source of
*HS-NAICS matches.
use `zzz'temp_01, clear
collapse (mean) naics87, by(naics)
rename naics87 naics87_new1
rename naics naics_new1
drop if naics_new1=="" | naics87_new1==.
sort naics87_new1
save `zzz'temp1, replace
use `zzz'temp_01, clear
collapse (mean) naics87, by(naics)
rename naics87 naics87_new2
rename naics naics_new2
drop if naics_new2=="" | naics87_new2==.
sort naics87_new2
save `zzz'temp2, replace
*First Mechanical Match
*Look at NAICS matches for HS10s within an HS9. If all non-missing
*NAICS codes are the same, assign that NAICS code to unmatched HS10s within
*that HS9. Repeat for higher levels of aggregation.
use `zzz'temp_01, clear
gen naics87_new1 = naics87
sum hs naics87*
quietly {
foreach x in 9 8 7 6 5 4 3 2 {
noisily display [`x']
local y = 10-`x'
gen hs`x' = int(hs/(10^`y'))
egen t1 = mean(naics87), by(hs`x')
egen t2 = sd(naics87), by(hs`x')
egen t3 = count(naics87), by(hs`x')
gen naics87_`x' = t1 if t2==0 | t3==1
replace naics87_new1 = naics87_`x' if naics87==. & naics87_new1==.
drop t1 t2 t3
drop hs`x' naics87_`x'
}
}
sum hs naics87 naics87_new1
sort hs
save `zzz'temp_02, replace
*Second Mechanical Match
*Sort HS codes. For unmatched HS codes (or contiguous groups of HS10
*codes), look at the matched HS10 codes that precede and follow. If
*matches for preceding and following HS10 codes are identical, assign
*that NAICS code to the unmatched HS code(s).
use `zzz'temp_02, clear
gen naics87_new2 = naics87_new1
gen begin = 1 if naics87_new1==. & naics87_new1[_n-1]~=.
gen end = naics87_new1==. & naics87_new1[_n+1]~=.
gen bsum = sum(begin)
gen gap = naics87_new1==.
replace bsum=. if gap==0
gen sb = naics87_new1[_n-1]*begin
gen se = naics87_new1[_n+1]*end
egen tb = mean(sb), by(bsum)
egen te = mean(se), by(bsum)
gen match = tb==te
replace naics87_new2 = tb if match==1 & naics87_new1==.
sum hs naics87*
drop begin end bsum gap sb se tb te match
sort hs
save `zzz'temp_03, replace
*Merge in "group" codes created above, which are only used for labeling.
use `zzz'temp_03, clear
sort naics87_new1
merge naics87_new1 using `zzz'temp1, keep(naics_new1)
tab _merge
drop _merge
sort naics87_new2
merge naics87_new2 using `zzz'temp2, keep(naics_new2)
tab _merge
drop _merge
sort hs
gen t=naics87_new1~=.
tab t
drop t
drop naics87*
format hs %15.0g
drop if hs<100
save `zzz'_concord_89_117_naicsfillin, replace
}
**3 Add in hand matches to imports and exports, respectively, first for sic and then for naics
* Any missing matches after the last section were matched by hand by kitjawat. Add these
* hand matches into the data here and then also create a variable that identifies each
* mapping according to whether it is from Census, mechanical match 1, mechanical match 2 or
* from kitjawat's hand matching.
*
* 2009.10.16 change sic 2612 to 2621 in kitjawat_handmatch_imports_sic_20080821 per Justin's email
* also add leading zero to sics from handmatch and fix missing naics for 1605106000
*
*imports
cd "$C"
use interim/m_concord_89_117_sicfillin, clear
sort hs
merge hs using input/kitjawat_handmatch_imports_sic_20080821
tab _merge
drop if _merge==2
*Correction of typo
replace kitjawat = 2621 if kitjawat==2612
drop _merge
tostring kitjawat, g(kitjawats)
replace kitjawats = "0"+kitjawats if kitjawat>=100 & kitjawat<=999
gen id = "From Census"
gen newsic = sic
replace id = "From mechanical match 1" if sic==""
replace newsic = sic_new1 if sic==""
replace id = "From mechanical match 2" if newsic==""
replace newsic = sic_new2 if newsic==""
replace id = "From hand match" if newsic==""
replace newsic = kitjawats if newsic==""
label var id "SIC match type"
keep commodity hs newsic id
rename newsic sic
rename id sic_matchtype
rename sic new_sic
keep commodity new_sic sic_matchtype
order commodity new_sic sic_matchtype
sort commodity
save interim/sic_m_final, replace
cd "$C"
use interim/m_concord_89_117_naicsfillin, clear
sort hs
merge hs using input/kitjawat_handmatch_imports_naics_20081016
tab _merge
drop if _merge==2
drop _merge
tostring kitjawat, g(kitjawats)
*Correct typo
replace kitjawats = "311711" if commodity==1605106000
gen id = "From Census"
gen newnaics = naics
replace id = "From mechanical match 1" if naics==""
replace newnaics = naics_new1 if naics==""
replace id = "From mechanical match 2" if newnaics==""
replace newnaics = naics_new2 if newnaics==""
replace id = "From hand match" if newnaics==""
replace newnaics = kitjawats if newnaics==""
label var id "NAICS match type"
drop naics
rename newnaics naics
rename id naics_matchtype
rename naics new_naics
keep commodity new_naics naics_matchtype
order commodity new_naics naics_matchtype
sort commodity
save interim/naics_m_final, replace
*exports
cd "$C"
use interim/x_concord_89_117_sicfillin, clear
sort hs
merge hs using input/kitjawat_handmatch_exports_sic_20080821
tab _merge
drop if _merge==2
drop _merge
tostring kitjawat, g(kitjawats)
replace kitjawats = "0"+kitjawats if kitjawat>=100 & kitjawat<=999
gen id = "From Census"
gen newsic = sic
replace id = "From mechanical match 1" if sic==""
replace newsic = sic_new1 if sic==""
replace id = "From mechanical match 2" if newsic==""
replace newsic = sic_new2 if newsic==""
replace id = "From hand match" if newsic==""
replace newsic = kitjawats if newsic==""
label var id "SIC match type"
drop sic
rename newsic sic
rename id sic_matchtype
rename sic new_sic
keep commodity new_sic sic_matchtype
order commodity new_sic sic_matchtype
sort commodity
save interim/sic_x_final, replace
cd "$C"
use interim/x_concord_89_117_naicsfillin, clear
sort hs
merge hs using input/kitjawat_handmatch_exports_naics_20081016
tab _merge
drop if _merge==2
drop _merge
tostring kitjawat, g(kitjawats)
gen id = "From Census"
gen newnaics = naics
replace id = "From mechanical match 1" if naics==""
replace newnaics = naics_new1 if naics==""
replace id = "From mechanical match 2" if newnaics==""
replace newnaics = naics_new2 if newnaics==""
replace id = "From hand match" if newnaics==""
replace newnaics = kitjawats if newnaics==""
label var id "NAICS match type"
drop naics
rename newnaics naics
rename id naics_matchtype
rename naics new_naics
keep commodity new_naics naics_matchtype
order commodity new_naics naics_matchtype
sort commodity
save interim/naics_x_final, replace
**4 Check how many naics are in concordance but not official list, and vice versa.
*Then, create a new NAICS code, NAICSX, that for a given parent will replace all
*children's codes with the parent root and X(s) if one or more children are missing from
*the census concordances.
*
*
*4.0 Assemble full list of naics codes by vintage
*
* Assume here that:
*
* 1997 codes used from 1989-2001
* 2002 codes used from 2002-2006
* 2007 codes used from 2007-2012
* 2012 codes used from 2013-2017
* 2017 codes used for 2017
*
* List of NAICS codes avaialable at:
* https://www.census.gov/eos/www/naics/concordances/concordances.html
*
*
*6-digit
cd "$NC"
foreach y in 1989 {
use naics_1997, clear
duplicates drop
gen year=1989
forvalues c=1/7 {
append using naics_1997
replace year=`y'+`c' if year==.
}
drop if naics97==.
save naics_1989_year, replace
}
tab year
foreach y in 1997 2002 {
use naics_`y', clear
duplicates drop
gen year=`y'
forvalues c=1/4 {
append using naics_`y'
replace year=`y'+`c' if year==.
}
capture drop if naics97==.
capture drop if naics02==.
save naics_`y'_year, replace
}
tab year
cd "$NC"
foreach y in 2007 {
use naics_2007, clear /*end 2007 a year later*/
duplicates drop
gen year=2007
forvalues c=1/5 {
append using naics_2007
replace year=`y'+`c' if year==.
}
drop if naics07==.
save naics_2007_year, replace
}
tab year
foreach y in 2012 {
use naics_2012, clear /*start 2012 a year late*/
duplicates drop
gen year=2013
forvalues c=1/4 {
append using naics_2012
replace year=`y'+`c' if year==.
}
drop if naics12==.
save naics_2012_year, replace
}
tab year
foreach y in 2017 {
use naics_2017, clear /*start 2012 a year late*/
duplicates drop
gen year=2017
drop if naics17==.
save naics_2017_year, replace
}
tab year
use naics_1989_year, clear
append using naics_1997_year
rename naics97 naics02
append using naics_2002_year
rename naics02 naics07
append using naics_2007_year
rename naics07 naics12
append using naics_2012_year
rename naics12 naics17
append using naics_2017_year
rename naics17 naics
drop title*
drop *title
gen i = 1
rename naics nnaics
tostring nnaics, force g(naics)
duplicates drop
save naics_year, replace
tab year
*how many man codes in above
use naics_year, clear
gen man =substr(naics,1,1)=="3"
egen x = tag(naics year)
table year if x, c(sum man)
*5-digit
cd "$NC"
use naics_year, clear
keep naics year
gen naics5 = substr(naics,1,5)
keep naics5 year
duplicates drop
save naics5_year, replace
*4-digit
cd "$NC"
use naics_year, clear
gen naics4 = substr(naics,1,4)
keep naics4 year
duplicates drop
save naics4_year, replace
*4.1 Merge official NAICS lists assembled above into HS-NAICS concordance
foreach t in m x {
cd "$C"
use interim/concord_`t'_1989_2017_abbreviated, clear
sort commodity
merge commodity using interim/sic_`t'_final
tab _merge
drop _merge
replace sic_matchtype="From Census" if sic!=""
replace sic=new_sic if sic=="" & new_sic!=""
sort commodity
merge commodity using interim/naics_`t'_final
tab _merge
drop _merge
replace naics_matchtype="From Census" if naics!=""
replace naics=new_naics if naics=="" & new_naics!=""
drop new*
destring commodity, g(hs) force
drop if commodity==.
order commodity year sic sic_matchtype naics naics_matchtype
sort commodity year
format commodity %15.0fc
gen double hs=commodity
*Label which codes are only in trade concordances, only in official
*NAICS list, or both
merge m:1 naics year using input/naics/naics_year
egen x = tag(naics year)
gen man = substr(naics,1,1)=="3"
tab _merge
table year _merge if x, c(sum man)
gen naics_origin = ""
replace naics_origin = "in concordance only" if _merge==1
replace naics_origin = "in official naics list only" if _merge==2
replace naics_origin = "in both concordance and official naics list" if _merge==3
*Create variable naicsX that replaces last character of NAICS with
*X if 5-digit parent is missing a child, where missing refers to
*a NAICS codes that is in the official list but doesn't appear in the
*trade concordances from Census.
gen naicsX = naics
gen n5 = substr(naics,1,5)
gen aa = _m==1
gen bb = _m==2
gen cc = aa | bb
egen t0 = total(bb), by(n5 year)
replace naicsX = n5+"X" if t0~=0
sort year naics
rename _merge _merge6
drop t0 n5 aa bb cc
*Go up a level of aggregation, (look for missing N5, within N4, and
*change naicsX to N4+"XX"
drop if _merge6==2
gen naics5 = substr(naics,1,5)
merge m:1 naics5 year using input/naics/naics5_year
drop x
egen x = tag(naics5 year)
tab _merge
table year _merge if x, c(sum man)
gen n4 = substr(naics5,1,4)
gen aa = _merge==1
gen bb = _merge==2
gen cc = aa | bb
egen t0 = total(bb), by(n4 year)
gen naicsX_old = naicsX
sort naics5
replace naicsX = n4+"XX" if t0~=0
rename _merge _merge5
drop if _merge5==2
sort year naicsX
drop t0 n4 aa bb cc naicsX_old
*Go up a level of aggregation, (look for missing N4, within N3, and
*change naicsX to N3+"XXX"
gen naics4 = substr(naics,1,4)
merge m:1 naics4 year using input/naics/naics4_year
drop x
egen x = tag(naics4 year)
tab _merge
table year _merge if x, c(sum man)
gen n3 = substr(naics4,1,3)
gen aa = _merge==1
gen bb = _merge==2
gen cc = aa | bb
egen t0 = total(bb), by(n3 year)
gen naicsX_old = naicsX
sort naics4
replace naicsX = n3+"XXX" if t0~=0
rename _merge _merge4
drop if _merge4==2
sort year naicsX
drop t0 n3 aa bb cc naicsX_old
*List the XXXs, XXs and Xs that are created in the preceding blocks
*
* 11119X 11133X 11141X 11251X 21211X 21223X 21231X 21232X 31131X 31135X
* 31141X 31161X 31171X 31199X 31311X 31322X 31324X 31331X 32121X 32191X
* 32222X 32223X 32311X 32312X 32531X 32541X 32599X 32629X 32733X 33142X
* 33151X 33152X 33211X 33231X 33261X 33299X 33311X 33331X 33351X 33391X
* 33411X 33461X 33512X 33522X 33611X 33631X 33699X 33712X 33721X 33911X
* 33993X 33999X
*
* 1121XX 1123XX 2111XX 3113XX 3118XX 3122XX 3133XX 3151XX 3152XX 3241XX
* 3261XX 3273XX 3312XX 3315XX 3327XX 5241XX
*
* 113XXX 114XXX 332XXX 511XXX 524XXX
*
*
gen n=strpos(naicsX,"X")
tab year n
tab naicsX if n==4
tab naicsX if n==5
tab naicsX if n==6
if "`t'" == "m" {
local tt = "imports"
}
if "`t'" == "x" {
local tt = "exports"
}
keep commodity year sic sic_matchtype naics naicsX naics_matchtype
sort year commodity
cd "$C"
save hs_sic_naics_`tt'_89_117_20180927, replace
outsheet using hs_sic_naics_`tt'_89_117_20180927.csv, replace
}
Implications for Data Provenance Documentation and Visualisation
- Graph/Matrix structure enables new insights from existing cross-taxonomy transformations
- Identification and summary of influential sub-graphs (i.e. one-to-many links are more subjective than one-to-one)
- Extracting transformation logic from existing algorithms (i.e. using unit vectors to trace the distribution of values)
- Crossmaps connect data transformation with established visualisation literature:
- Bi-graph visualisation (upcoming workshop at IEEE VIS23)
- Multi-layer graph visualisation and layout algorithms for sequential transformations
- Interactive exploration of transformation mappings
Implementation in R {xmap}
Considerations and features
- new vector types to handle category index vectors (factor+) and roles (i.e. to, from, weights)
- new data-frame types for storing and validating crossmap edge-lists
- nested workflows for handling multiple related transformations
- floating point tolerance for validating weights (i.e. what is close enough to
1?) - helper functions for converting crossmaps to/from other formats (matrices, igraph etc.)
- helper functions for generating valid crossmaps and sample source data to simulate cross-taxonomy transformations
- helper functions for converting crossmap edge-lists into provenance documentation
New Provenance Documentation Formats
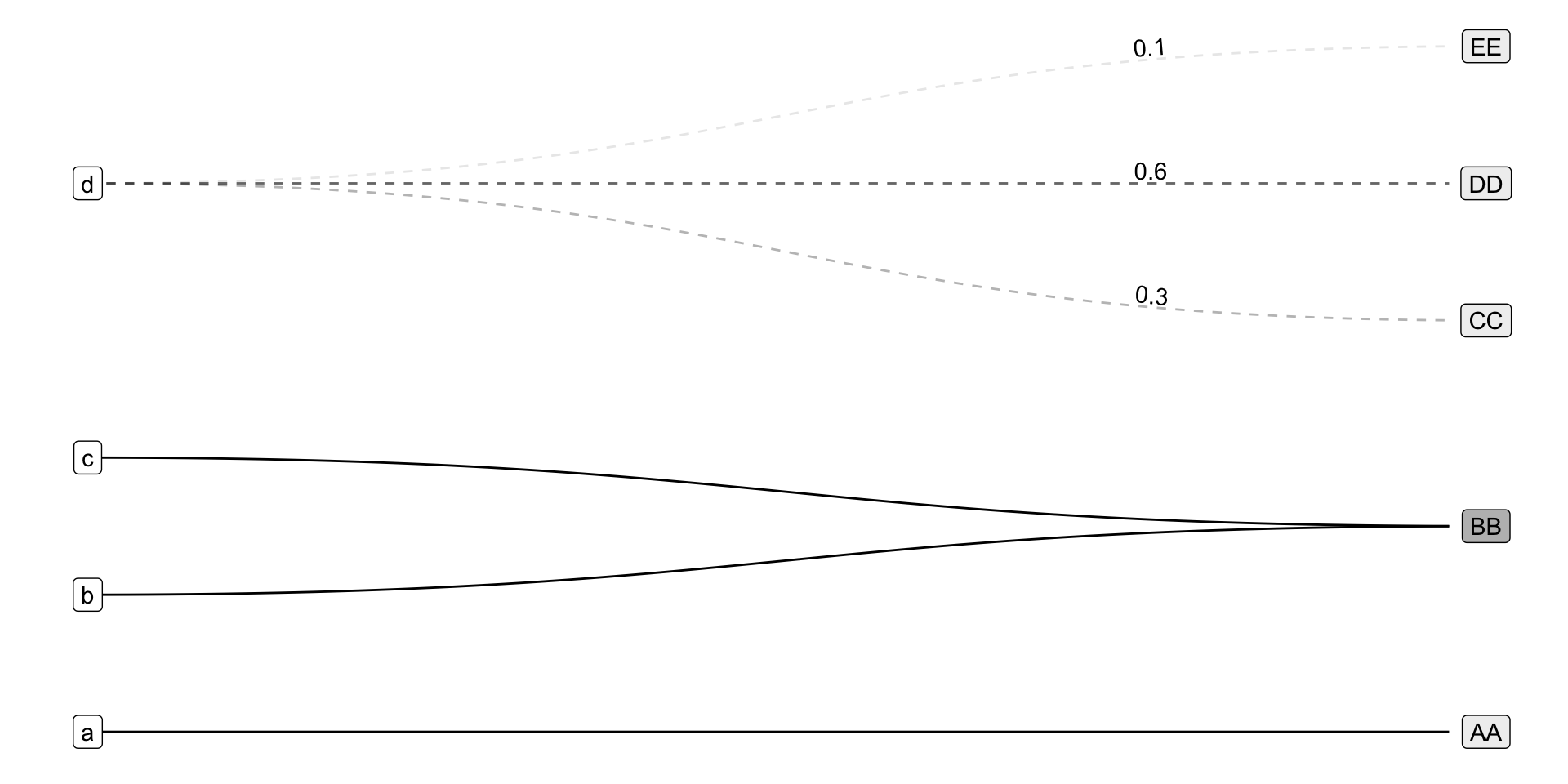
References

NUMBATS Seminar
Blocker, Alexander W., and Xiao-Li Meng. 2013. “The Potential and Perils of Preprocessing: Building New Foundations.” Bernoulli 19 (4). https://doi.org/10.3150/13-BEJSP16.
Ehling, Manfred. 2003. “Harmonising Data in Official Statistics.” In Advances in Cross-National Comparison, edited by Jürgen H. P. Hoffmeyer-Zlotnik and Christof Wolf, 17–31. Boston, MA: Springer US. https://doi.org/10.1007/978-1-4419-9186-7_2.
Fortier, Isabel, Parminder Raina, Edwin R Van Den Heuvel, Lauren E Griffith, Camille Craig, Matilda Saliba, Dany Doiron, et al. 2016. “Maelstrom Research Guidelines for Rigorous Retrospective Data Harmonization.” International Journal of Epidemiology, June, dyw075. https://doi.org/10.1093/ije/dyw075.
Kandel, Sean, Andreas Paepcke, Joseph Hellerstein, and Jeffrey Heer. 2011. “Wrangler: Interactive Visual Specification of Data Transformation Scripts.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 3363–72. Vancouver BC Canada: ACM. https://doi.org/10.1145/1978942.1979444.
Kołczyńska, Marta. 2022. “Combining Multiple Survey Sources: A Reproducible Workflow and Toolbox for Survey Data Harmonization.” Methodological Innovations 15 (1): 62–72. https://doi.org/10.1177/20597991221077923.
Wickham, Hadley. 2014. “Tidy Data.” Journal of Statistical Software 59 (10). https://doi.org/10.18637/jss.v059.i10.